反向傳播演算法(Back propagation)(1) — 小簡介
一個非常惱人,不想去深入了解,卻又很重要的概念。對於深度學習非常重要,可以說是劃時代的里程碑之一,但不好解釋清楚。概念本身具有層次感,以為了解了,過一段時間再看還會有新的發現。不了解它也可以操作深度學習的神經網路,但要深究直指本源,還是不能不看它。
這講的就是反向傳播演算法。也可以說是學習深度學習的縮影。
從一本書裡面看到了分析和講解這個觀念,覺得還不錯,就整理記錄下來。
2023/07/04紀錄:
本文將會逐步修訂,以希望保持正確的形況下,兼顧翻譯通暢性。歡迎舊雨新知有空再回來看看。
2023/08/30紀錄:
本文修訂完成。
關於損失函數的兩個假設
神經網路的公式為

其中 σ 為啟動函數,a 為輸出,b 為誤差,w 為權重。l-1 為上一層,l 為本層。
損失函數(以quadratic cost為例)的公式則為

反向傳播的目標是對於神經網路中的權重 w 和誤差 b ,可以找到 C 對 b 和 w 的偏微分。為什麼要找偏微分?因為微分/導數代表函數的切線斜率,在函數的最大/最小值,其切線斜率為 0。所以,如果我們想減少損失函數的值,就應該先求得其切線斜率,並試著逼近 0。或者說,梯度為 0。這也是為什麼我們選擇損失函數或啟動函數時,會希望函數可微分的原因。
在這之前,要先設定兩個假設。
第一,損失函數 C 可以視為每筆訓練資料 x 之損失函數 Cx 之平均。以公式2.為例,單筆資料的損失函數為

這個假設的目的是,實際上反向傳播演算法是看每一筆資料的損失函數的偏微分的。利用一群體資料的損失函數 C 來代替個體 Cx,則損失函數要用平均來代替單筆。在這個情況下可以暫時把 x 視為固定值。
第二個假設是把損失函數視為神經網路輸出的函數。例如:

由於 x 固定了, y 也固定,就可以把整個函數視為是 C 對 a — 也就是經過啟動函數之後的輸出 — 的函數了。
另外,為了後面討論及記錄方便,有時會用以下式子:
z為本層神經元運算之後,尚未進入啟動函數的值,稱為「加權輸入」(weighted input)。因此
阿達瑪乘積(Hadamard product)
在神經網路中我們頻繁的使用線性代數裡矩陣和向量的乘積,以及相加等概念。其中一個較少被提到的是阿達瑪乘積。假設 s 和 t 為同樣維度的向量,s⊙t 即為 s 和 t 的阿達瑪乘積,其過程為 elementwise,即對應位置的元素相乘。如下:

這在反向傳播運算中會用到。
反向傳播演算法背後的四個基礎公式
先引進一個觀念,δ。它是一個中間變量,作為損失函數和每一層權重/誤差的橋樑。給它一個名稱叫「偏誤」(error),屬於單一個神經元。如果要標示第 l 層中第 j 個神經元的偏誤,就表示為

反向傳播演算會先取得偏誤,再連到 C 對 w、b 的偏導數。
偏誤在某個神經元添加了一點加權輸入 △z,使得最後進入啟動函數的輸入不是原本的 z,而是 z+△z。這樣的變化會傳播到最後,並導致損失函數對z的偏導數
的變化。在讓損失函數C越低越好的前提下,若偏導數
是一個大值,則只要讓整個值為負,△z 的些微變化就可以做到;反之,若偏導數趨近於 0,表示該神經元對於整個神經網路並不是那麼重要,則 △z 的變化對損失函數的影響就不明顯。如此可以得到 δ 對偏導數的關聯,可以把偏導數看成一種測量 δ 的方法。某種程度而言,可以表示為:

至於為何是用偏誤的變化 △z 而非啟動函數?事實上用啟動函數也可以得到類似的結論,但在代數的表現上會複雜一點。所以先用上面的概念吧。
以下的四個公式會協助我們從計算 δ 以及損失函數的梯度。按照書中的敘述,其順序會從對公式的簡單證明開始,然後再把公式用 pseudocode 來描述一遍,再以程式語言落實公式。最後,會用一個直觀的描述來解釋反向傳播演算法的意義。
其一:對於輸出層的偏誤的表示式
第 L 層的 δ,可表示為

這是一個很直觀的式子。偏誤受到神經元對於神經網路的重要性,以及啟動函數影響。
對應的是第 j 個輸出,其變化會對應損失(C)變化的速度。假如損失不太受這個神經元的影響,則 δ 就會很小。
則表示啟動函數 σ 的變化速度和特定加權輸入z的關聯性。
公式6基本上好計算。z 本身是神經網路運算的結果,所以只需再花一點工夫就能得到σ’ (z)。偏微分的部分則取決於損失函數的使用。例如我們選用 quadratic cost function,則 C 為

而偏微分的結果變成

如此要計算就簡單得多。
這是一個 δ 的分解式,裡面的元素就是影響 δ 的因素,但它不是以矩陣的方式呈現。如果要改寫成矩陣表示式,要改寫為

▽aC 對應的是 C 對 a 的偏微分。除此之外都相同,公式6和7的代換很簡單。為求方便,接下來都會用公式6來推演。如果 C 選用 quadratic cost function,則用矩陣表示的式子改寫為

很直觀。而且這個式子可以直接利用 python 的 package(例如numpy)寫出來,對於實作很有幫助。
其二:以下一層(l+1)的偏誤來表示本層偏誤
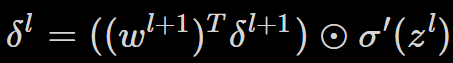
w 指的是權重,T 表示矩陣的轉置。整個式子看起來複雜,不過各元素有其代表意義。文章中作者直接建議讀者把 w 的轉置矩陣直觀的視為一種「逆推」,也就是帶有反向傳播的意義在裡面。其實這牽涉到轉置矩陣的數學意義,但轉置矩陣的定義雖然簡單,背後的數學意義卻一言難盡。快速翻查了一下[1],個人認為可以把它理解成「反向映射」--和作者的建議雷同,但不完全相等--因為反向映射到的子空間y並不等同於正向映射的子空間 x,只能說兩者在同一個向量空間裡面。不過這樣的理解也有一點幫助,深入的追究就等到這章看完之後有空再說吧。
接著是式子右側

這是一個阿達馬乘積,目的在將 l+1 層的損失「傳」回上一層,也就是 l層。經由什麼呢?啟動函數 σ。
所以這個公式的精神是:下一層的偏誤和下一層的加權輸入有關,透過轉置權重,反推回本層的輸出,再透過啟動函數,對應到本層的加權輸入。
結合目前提到的兩個公式,我們可以求出神經網路中任何一層的損失。利用公式6求最後一層(損失函數對應的是最後一層),然後用公式8反推。
其三:損失之於誤差變化率的表示式

偏誤等於損失函數對誤差的偏微分。這個公式好用之處在於從公式 6 和8,我們已經知道如何計算任何一個神經元的偏誤。所以透過這個公式,我們可以進一步知道:某個神經元的損失可以由誤差評估。
其四:損失之於權重變化率的表示式

這個公式告訴我們可以用前一層的輸出和本層的偏誤,計算損失函數對特定權重的偏微分。可以把它簡寫成

若把它畫成示意圖,可以畫成

這一層神經元的權重,和前一層神經元的輸出,以及本層的偏誤有關連。在這個算式中,如果輸出 a 非常低,例如接近 0,則偏微分的值也會很低。在這個情況下,會說是「權重學習很慢」--在梯度下降過程中,權重的影響對於損失影響不大,所以權重的更新很慢。這是公式10中的一個極端狀況。
這四個公式還可以推導一些概念。再回到輸出層,考慮公式6的右側,即
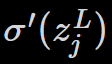
如果啟動函數使用 sigmoid,則根據其函數走向,在 y 值接近兩端的時候,曲線會變得非常平緩。在這兩個區間,偏微分的值會接近 0。從這裡可以得到如果輸出太低(0)或太高(1),則會導致偏微分的值偏低,學習就會慢。這樣的狀況就是俗稱的「飽和」,權重的更新會很慢,甚至停止學習。同樣的,從公式9可以得知在神經網路中的任何一層,也有可能出現飽和的狀況。
以上提到的狀況及四種公式,並不僅限於使用 sigmoid 作為啟動函數的時候才會出現。稍後的推導將解釋其通用性。我們甚至可以利用這些結果來「設計」啟動函數,例如非 sigmoid 函數,使 σ' 持續保持在正值,而不會變成0,進而避免飽和的情形發生。
反向傳播演算法的流程(algorithm)
把整個流程結合上面四個公式寫下來。類似 pseudocode 的概念。
- input x:設一個相對應輸入層的輸出 a。
- 正向傳播:每一層的神經網路遵守 z=a^lx+b,且 a^(l+1)=σ(z)。a^l是第 l 層的輸出,a^(l+1)則是第 l+1 層。
- 輸出損失:δ。在輸出層,利用公式6(7)計算。
- 反向傳播損失:利用公式8可以將損失反向傳播至每一層。
- 輸出:損失函數的梯度可以用公式10和公式11對應權重和誤差。
整個過程呼應最前面的假設:把損失視為一個函數。
在實務上,我們常常把反向傳播演算法結合一些梯度下降的手段(例如隨機梯度下降)運用。特別是利用批次(batch)訓練時,我們會在一個資料量為 m 的批次中執行以下步驟:
- 將整批次的資料輸入。
- 對於每一筆批次中的資料:
(1) 正向傳播:就像上面2.提到的。
(2) 輸出損失:就是3.。
(3) 反向傳播損失:就是4.。
3. 梯度下降:對每一層的權重和誤差,根據
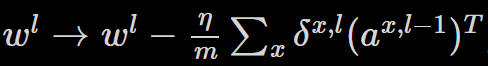
和

更新權重和誤差。其中 η 是學習速率。
這裡省略了資料產生器和針對每個輪數的步驟(step)的計算過程。
下一篇文章會先跳過程式實作的部分,進到後面的討論。之後再回到程式實作。
Reference
[1] 轉置矩陣的意義。https://ccjou.wordpress.com/2010/05/20/%E8%BD%89%E7%BD%AE%E7%9F%A9%E9%99%A3%E7%9A%84%E6%84%8F%E7%BE%A9/
